
TSN Simulation - NeSTiNg
一、简介
TSN(Time-Sensitive Networking)时间敏感网络,即在非确定性的以太网中实现确定性的最小时间延时的协议族,是IEEE 802.1工作组中的TSN工作组开发的一套协议标准。其定义了以太网数据传输的时间敏感机制,为标准以太网增加了确定性和可靠性,以确保数据实时、确定和可靠地传输。
OMNeT++(Objective Modular Network TestBed in C++) 是基于 Eclipse 开发的开源的基于组件的模块化的开放网络仿真平台,是近年来在科学和工业领域里逐渐流行的一种优秀的网络仿真平台。其作为离散事件仿真器,具备强大完善的图形界面接口和可嵌入式仿真内核,同NS2等仿真平台相比,OMNeT++可运行于多个操作系统平台,可以简便定义网络拓扑结构,具备编程,调试和跟踪支持等功能。
目前,OMNeT++中常用的TSN仿真库如下:
注意:本文主体是在2022年4月完成的,当时 NeSTiNg 还是不错的选择,但是今年6月推出的 INET 4.4 ,其功能完善并且文档齐全,更推荐直接学习 INET 4.4
二、搭建仿真环境
2.1 仿真环境
本文采用的仿真环境为:
| 版本 | 功能 | |
|---|---|---|
| Ubuntu | 18.04 | 仿真平台操作系统 |
| OMNeT++ | 5.5.1 | 仿真平台 |
| INET Framework | 4.1.2 | 提供多种网络协议仿真 |
| NeSTiNg | / | 提供多种TSN模型 |
2.2 编译安装
网上有大量OMNeT++的安装教程,在此不做赘述。具体可参照以下链接。
https://blog.csdn.net/weixin_37702021/article/details/121306656
https://doc.omnetpp.org/omnetpp/InstallGuide.pdf
2.3 常见问题
- 安装过程中不要使用root用户
- 配置过程中需要下载大量国外资源,建议配置apt代理和git代理,具体可参考此文章
三、仿真模型分析
在本章节,我们将根据ned文件描述,分析 NeSTiNg 中引入的TSN终端和TSN交换机模型具体功能及结构。
3.1 TSN交换机
3.1.1 交换机缓冲架构
一台交换机具有多个输入输出端口,交换机内部通过交换矩阵将端口连接起来。交换机内有一块资源存储缓冲区,用于存储待转发的数据包。根据缓冲区位置的不同,可以分为以下四种架构:
(a) 输出端口缓冲架构:将缓冲区置于出端口位置。其相比于输入端口缓冲具有更好的吞吐性。但每个输出端口需要 N 倍于线路带宽的处理能力来处理来自 N 个输入端口的帧,对处理芯片性能要求高。
(b) 输入端口缓冲+虚拟输出队列(VOQs)架构:可以满足处理速度,但吞吐量低,是目前最常用的架构。
(c) 交叉点缓冲架构:吞吐量大,但是对于具有N个端口的交换机需要O(N*N)的缓存空间。所需空间大,空间利用率低。
(c) 交换-内存-交换 (SMS) 架构:每个输入和输出端口共享中间的所有缓冲区,空间利用率高。

在 NeSTiNg 中提供了一个支持帧抢占的TSN交换机VlanEtherSwitchPreemptable,其采用输出端口缓冲的架构,流量在交换机中完成交换后,在对应输出端口中进行排队。如图2所示为TSN交换机的上半部分,主要负责对来自lowerLayer的流量进行转发,并将其传输至输出端口队列进行排队。
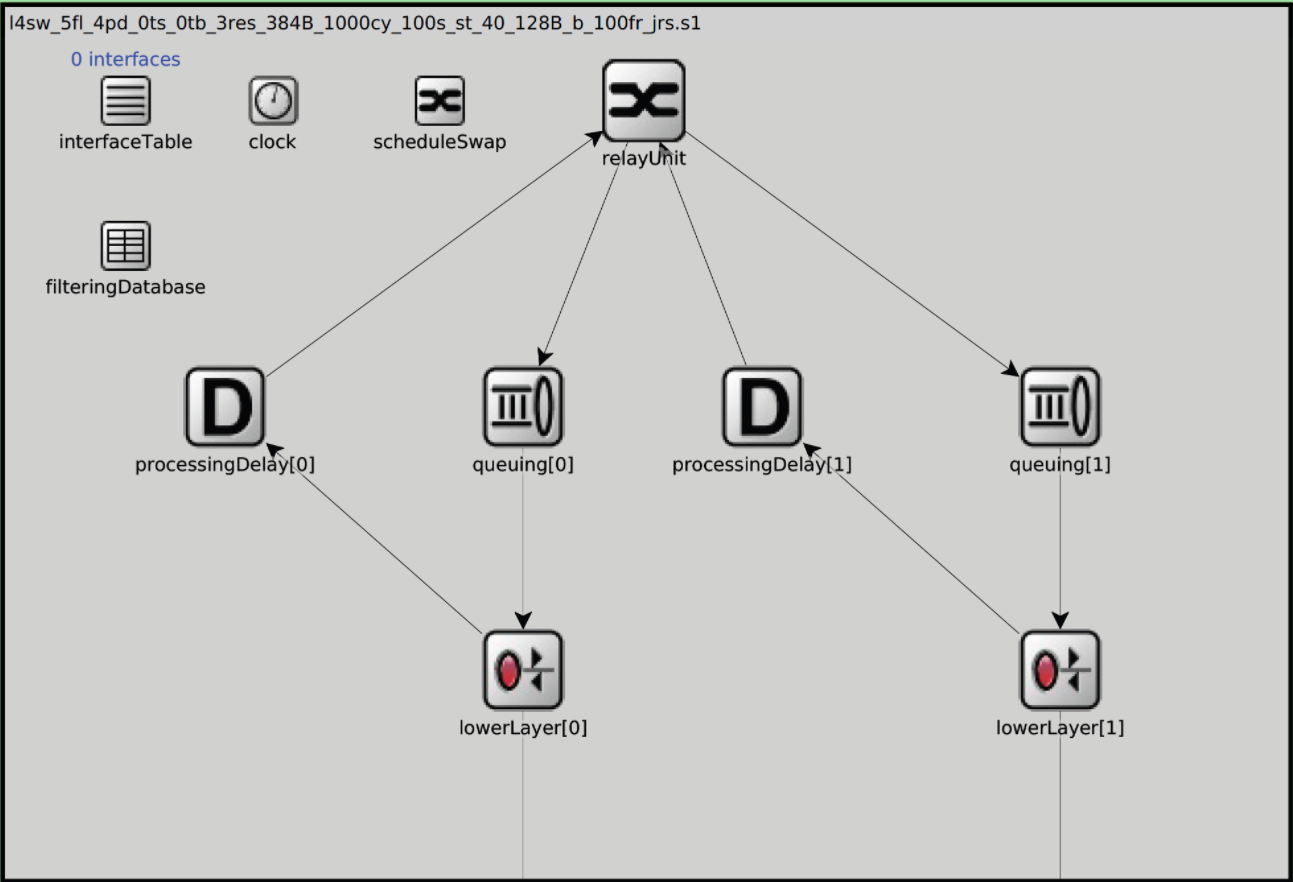
其上半部分涉及到的模块功能如下:
| 模块 | 功能 |
|---|---|
| interface Table | 负责将新接入交换机设备的mac地址和对应端口绑定 |
| Filtering Database | 过滤数据库负责存储数据包的过滤和转发规则,用于中继模块 |
| clock | 交换机时钟,负责时间同步 |
| scheduleSwap | 调度交换模块 |
| ProcessingDelay | 延迟模块,负责仿真流量在交换机内部寻找路由等所消耗时间 |
| relayUnit | 中继模块,负责仿真流量在交换机内部寻找目的端口 |
| queuing | 输出端口队列,存储转发至该端口待传输的数据包 |
| lowerLayer | 下层接口,负责将流量传入物理层传输 |
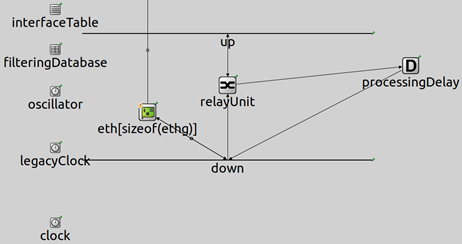
如图3所示为TSN交换机的下半部分,主要负责对来自MAC层的流量进行处理。
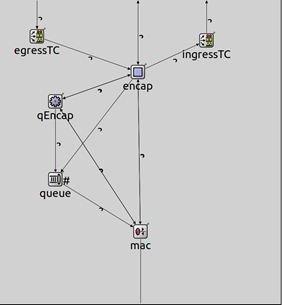
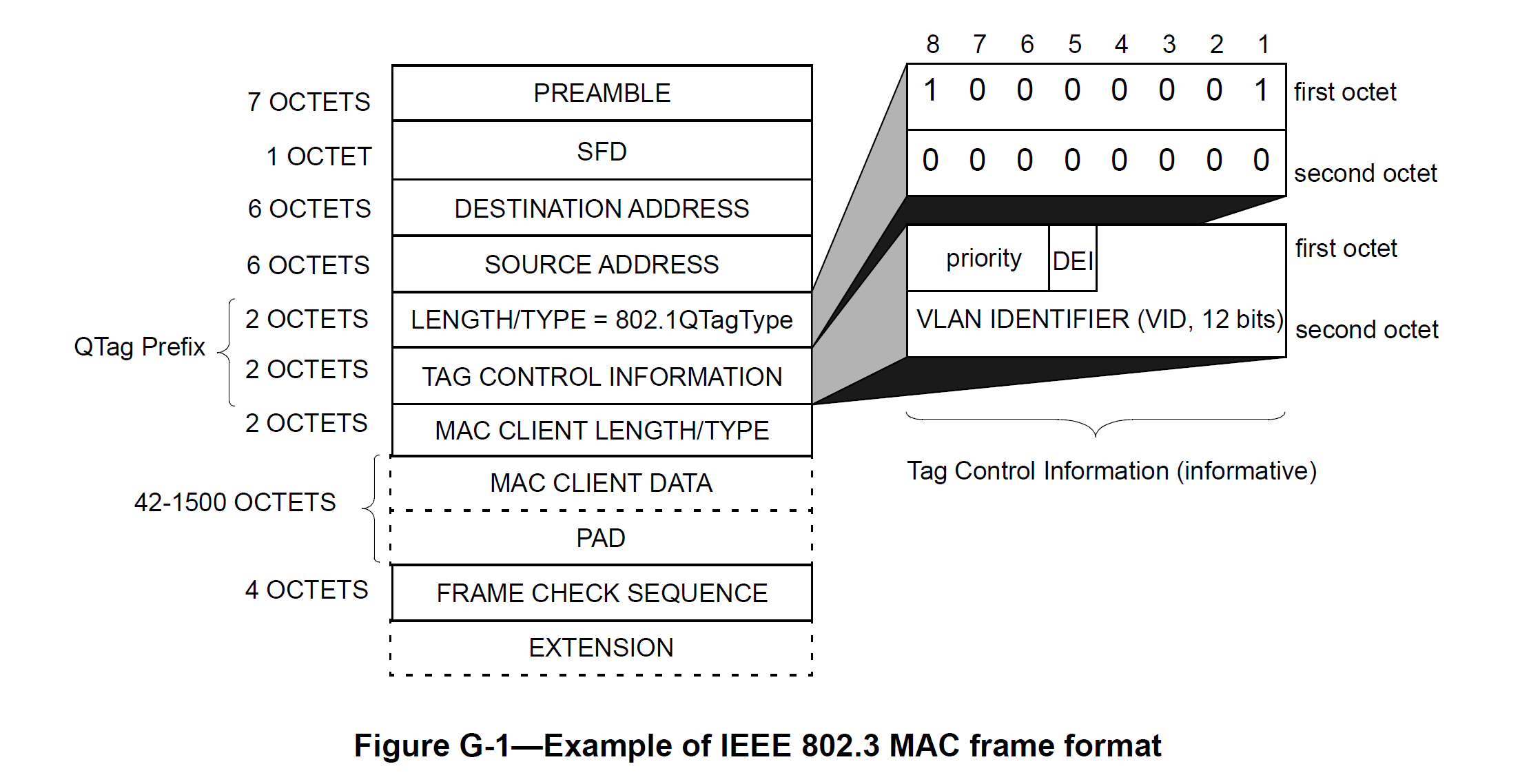
如图4所示为TSN交换机网卡中结构,流量从MAC层进入后,经由VLAN Tag处理和出入规则调节器( ingressTC , egressTC )后,进入TSN交换机。
如图5所示为输出端口队列(即图2中queuing)内部结构,由以下模块组成:
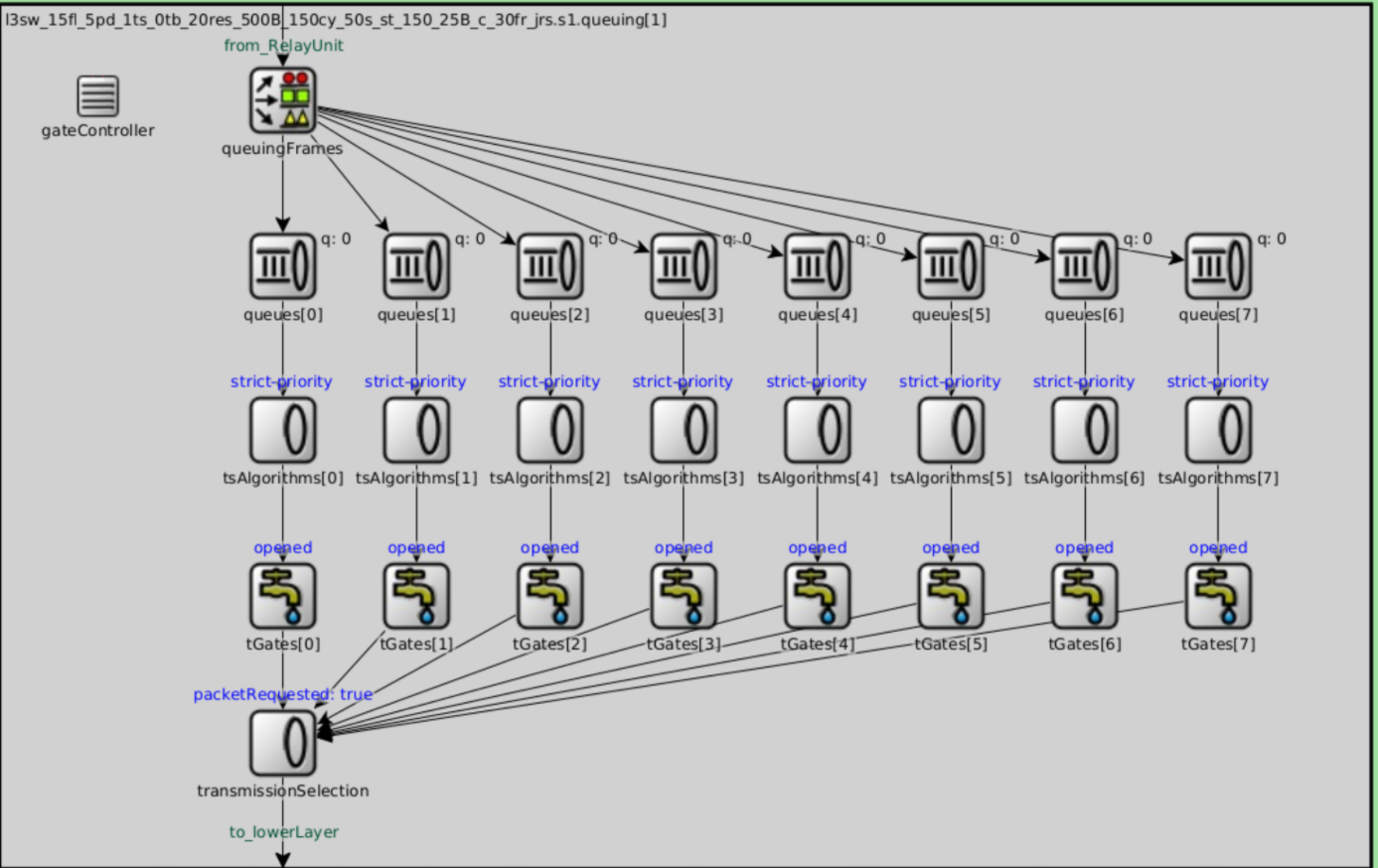
| 模块 | 功能 |
|---|---|
| gateController | 负责控制GCL,控制门(tGates)的开关 |
| queuingFrames | 负责根据数据帧Vlan Tag中的PCP值将其映射到不同队列中 |
| queues | 负责存储待转发的数据帧 |
| tsAlgorithms | 时间整形算法,根据一定的规则在队列中选择下一个待传输的数据帧。常见的算法有CBS等。 |
| tGates | 门控,当门打开时该队列流量可以传输 |
| transmissionSelection | 传输选择,当同一时间端口中有多个队列的流量都可传输时,选择优先传输的流量 |
在此,我们利用一个流量从交换机入端口(ingress)到出端口(egress)的流程来演示流量在交换机内部的操作。(条件设定:流量vlan pcp=7;当前时间=0s;processingDelay=5us;tsAlgorithms=FIFO;交换机内部端口队列中无存储流量,无正在传输流量;GCL=01111111 100us 10000000 100us;流量从0号端口入,1号端口出)
在端设备连接到交换机上时,interface Table在交换机内部将端口号与mac地址绑定。filtering Database存储数据包过滤与转发的规则。流量从0号端口进入交换机时,filtering Database决定是否接收该数据包,数据包从物理层经由lowerLayer[0]进入交换机,relayUnit根据流量目的地址,将其转发至1号端口。整个过程耗时5us。流量进入1号端口queuingFrames,其根据流量PCP值,将其映射至queues[7]等待传输。tsAlgorithms配置为FIFO模式,因此该流量在queues[7]中不在重新排队。此时时间为5us,tGates[7]=0,关门,7号队列流量无法传输。当时间到达100us时,tGates[7]=1,开门。流量进入transmissionSelection中,由于只有7号队列的流量,所以直接进入lowerLayer[1],传输至物理层。
3.2 TSN终端
3.2.1 VlanEtherHostSched
该模块实现了可根据给定时间表发送带有VLAN Tag数据的简单主机,一般充当实时性通信的双方。其具体结构如下图所示:
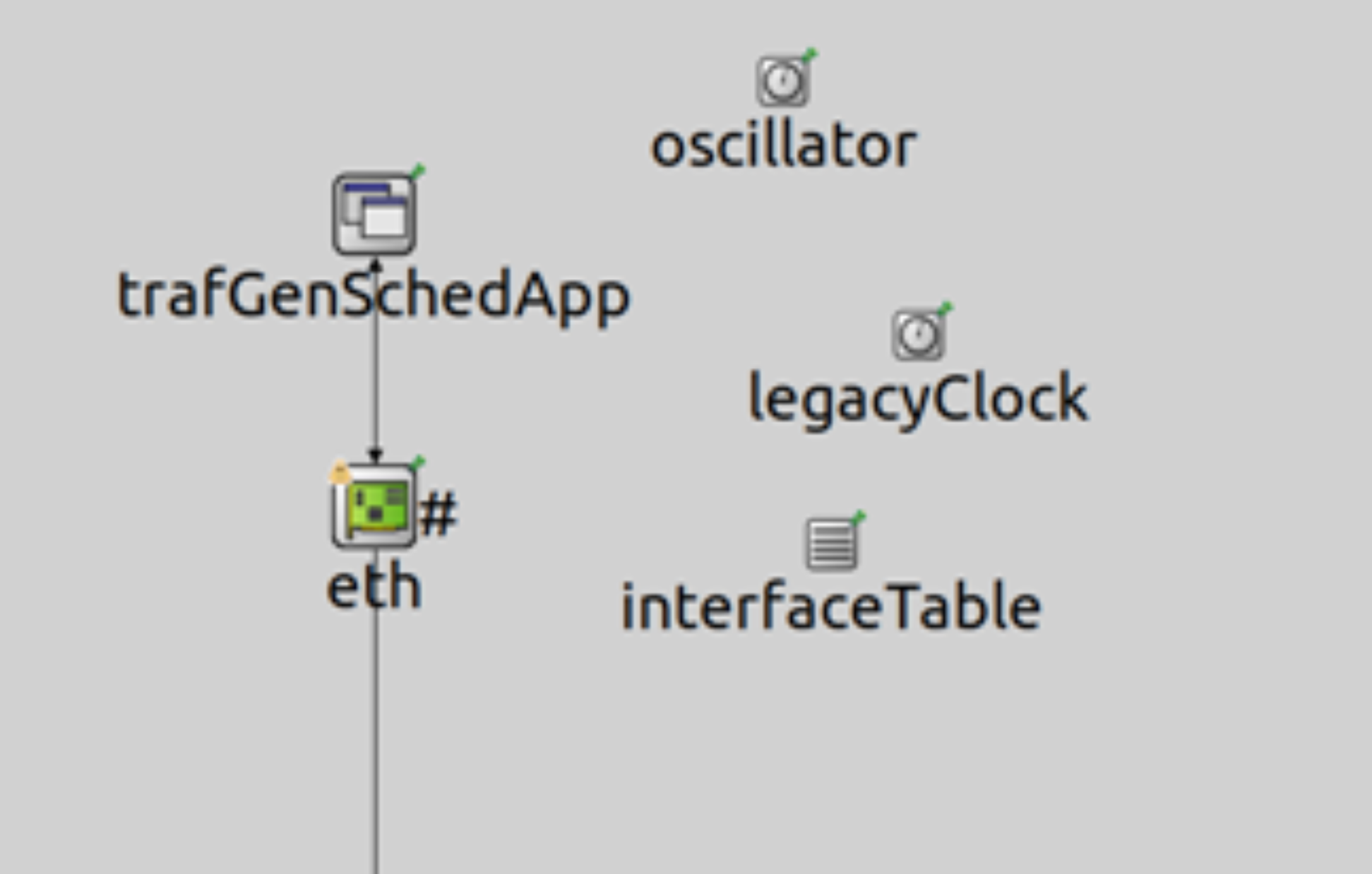
3.2.2 VlanEtherHostQ
该模块实现了可以发送带有VLAN Tag数据的简单主机,一般充当非实时性通信的双方。其具体结构如下图所示:
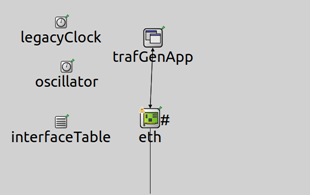
注意:VlanEtherHostQ、VlanEtherHostSched中以太网网卡模型与VlanEtherSwitchPreemptable中以太网网卡结构不同,此处暂不做分析。
四、仿真实验
在本章节,将结合 NeSTiNg论文 与源代码,分析其具体实现方式,并复现论文实验结果。NeSTiNg官方提供的3个例程模拟TSN网络。例程位于【 Nesting / simulation / examples】目录下,分别为:
- 01_example_strict_priority:严格优先级
- 02_example_gating:门控
- 03_example_frame_preemption:帧抢占
4.1 ned文件详解
在ned文件中,指出链路传播延迟=0.1us,链路带宽1Gbps。交换机采用VlanEtherSwitchPreemptable模型,robotController采用VlanEtherHostSched模型,其余终端采用VlanEtherHostQ模型。
3个例程采用同一个ned文件(TestScenario.ned)描述的网络拓扑。网络拓扑如下图所示,其中workstation1与workstation2向backupServer发送数据包,robotCotroller向roboticArm发生数据包。
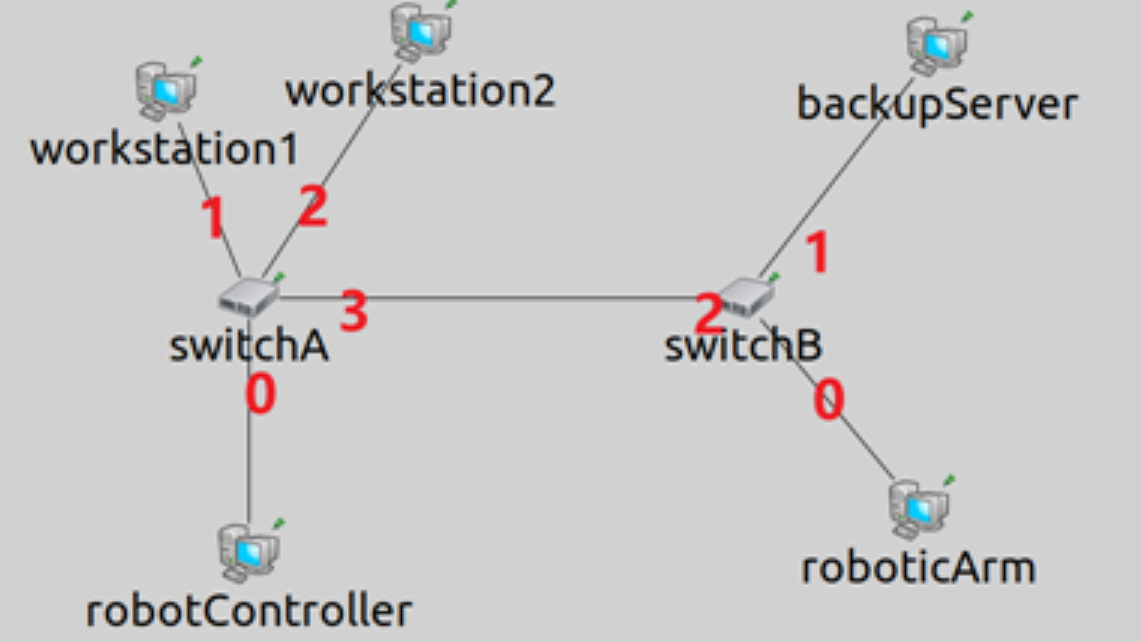
| 源 | 目的 | 优先级 | 发送间隔 | 帧大小 | 帧传输时间 |
|---|---|---|---|---|---|
| RobotController | RoboticArm | 7 | 400us | 354B | 2.832us |
| workStation1 | BackupServer | 6 | 12us | 1500B | 12us |
| workStation2 | BackupServer | 5 | 12us | 1500B | 12us |
4.2 严格优先级
4.2.1 example_strict_priority.ini文件
在本小节我们对01_example_strict_priority.ini文件内容进行全面的解析,对于另外两个ini文件我们仅描述其不同点。
1 | [General] |
4.2.2 TestScenarioSchedule_AllOpen.xml文件
1 |
|
4.2.3 StrictPriority算法
暂未了解算法具体代码。大体意思是流量严格按照高优先级到低优先级的顺序发送,只要有高优先级流量存在,低优先级就需要等待高优先级发送完成后才可发送。
4.2.4 实验结果
通过观察RoboticArm端应用程序统计的端到端延迟(endToEndDelay:vector TestScenario.roboticArm.tranfGenApp),可以看到延迟范围是19.5us-31.8us,且呈现一定的周期性。
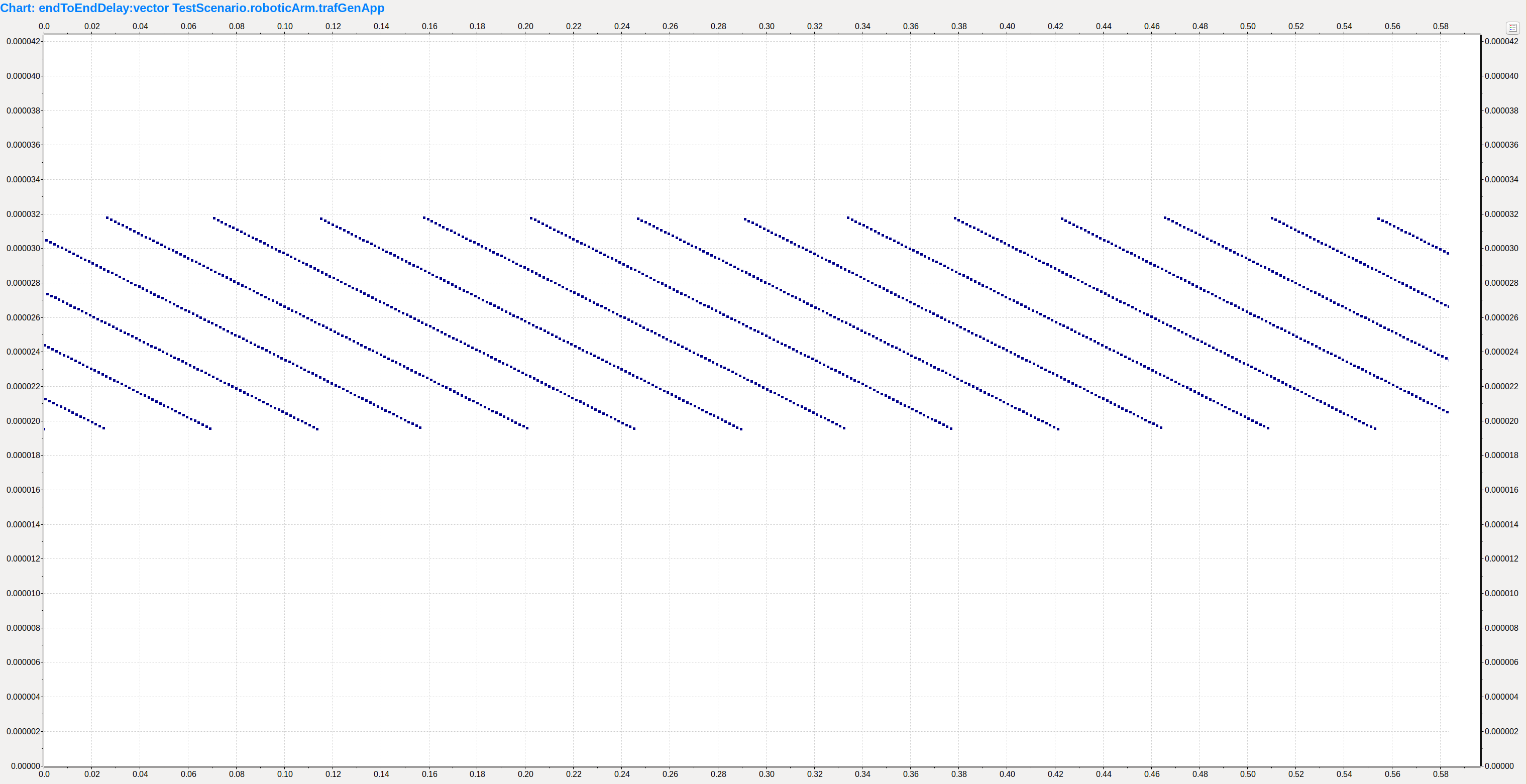
workStation1流量带宽为:0.987Gbps (TestScenario.workStation1.eth.mac bits/sec sent =986962179)
SwitchA.eth[3]流量带宽为:0.987Gbps(TestScenario.switchA.eth[3].mac bits/sec sent = 986655162)
robotController流量带宽为:0.0075Gbps (TestScenario.robotController.eth.mac bits/sec sent =7523725)
workStation2丢包率为:100% (TestScenario.switchA.eth[2].mac rx channel idle(%)=100)
4.2.5 小结
在严格优先级中,初始时刻,网络中仅workStation1和workStation2的流量,由于workStation1流量优先级较高,优先发送。当到达10us时,RobotController发出一个优先级为7的流量,但此时交换机中正在由流量被发送,因此需要等待到12us时才可从交换机中发出,产生约2us的排队时延。RobotController发送完成后,workStation1继续传输,由于流量间隔为12us,且workStation2流量优先级较低,所以workStation2的流量在SwitchA处一直排队,无法传输。
RobotController传输的最好情况是其流量到达交换机时刚好上一个流量传输完;最坏情况是刚好上一个流量开始传输。最好情况与最坏情况相差12us。

4.3 门控
4.3.1 example_gating.ini文件
02_example_gating.ini文件与01_example_strict_priority.ini文件相比主要不同点集中在以下三条配置。其指定RobotController和交换机都采用TestScenarioSchedule_GatingOn.xml文件描述的门控。
1 | **.switchA.eth[3].queue.gateController.initialSchedule = xmldoc("xml/TestScenarioSchedule_GatingOn.xml", "/schedules/switch[@name='switchA']/port[@id='3']/schedule") |
4.3.2 TestScenarioSchedule_GatingOn.xml文件
1 |
|
4.3.3 实验结果
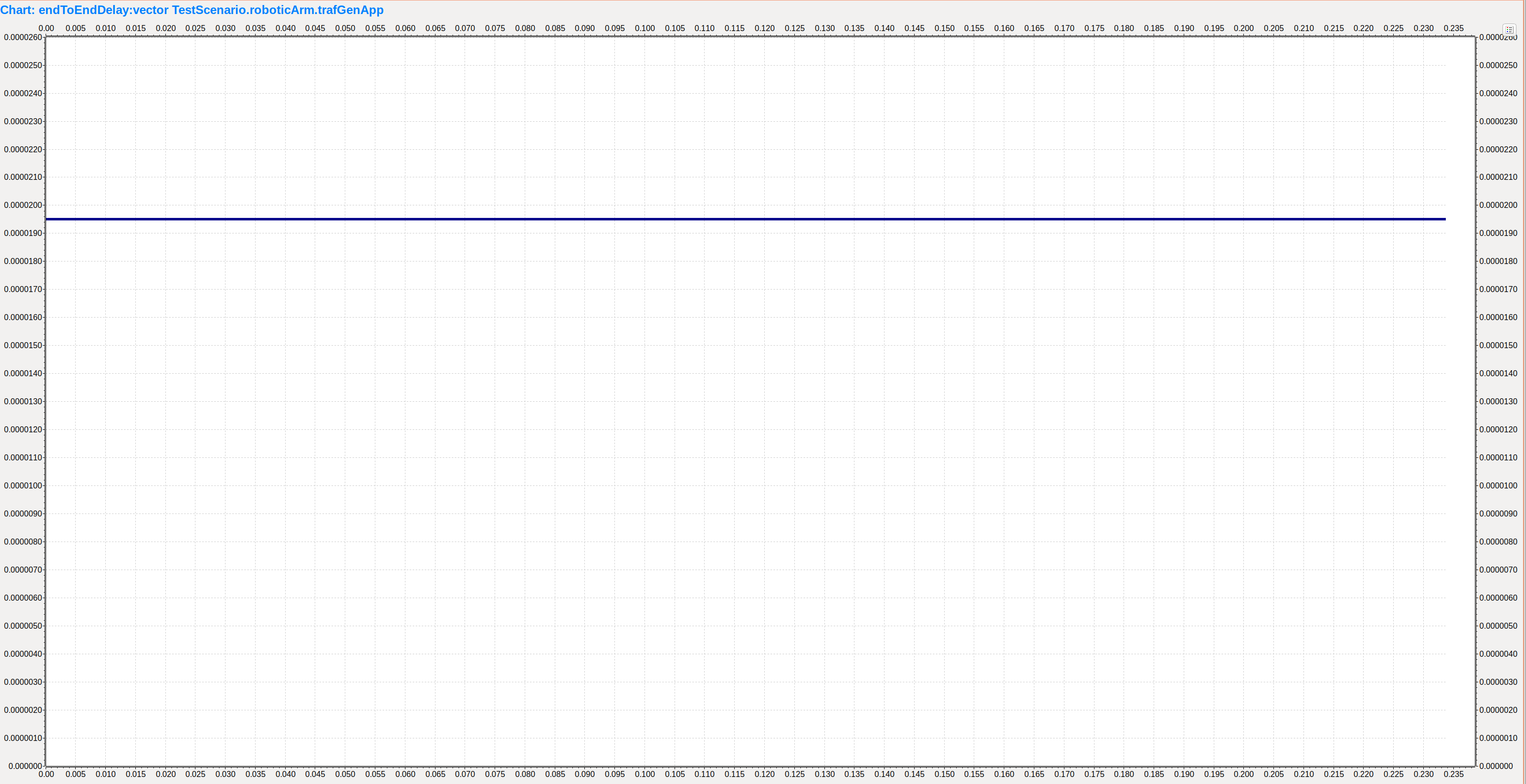
观察RoboticArm端应用程序统计的端到端延迟,可以看到延迟确定性极佳,稳定在19.5us
workStation1流量带宽为:0.987Gbps (TestScenario.workStation1.eth.mac bits/sec sent =986945179)
SwitchA.eth[3]流量带宽为:0.493Gbps(TestScenario.switchA.eth[3].mac bits/sec sent =492965016)
robotController流量带宽为:0.0075Gbps (TestScenario.robotController.eth.mac bits/sec sent =7523725)
workStation2丢包率为:100% (TestScenario.switchA.eth[2].mac rx channel idle(%)=100)
时间问题:按照Nesting论文中,dtot=3 *dprop+2*dproc+3*dtrans=19.516us。其中交换机处理延迟dproc=5us,链路传输延迟dtrans=0.1us,传播延迟(传输一帧用时) dprop=数据帧大小(应用层354B+802.3协议帧格式的30B=384B)/ 1Gbps = 3.072us
4.3.4 小结
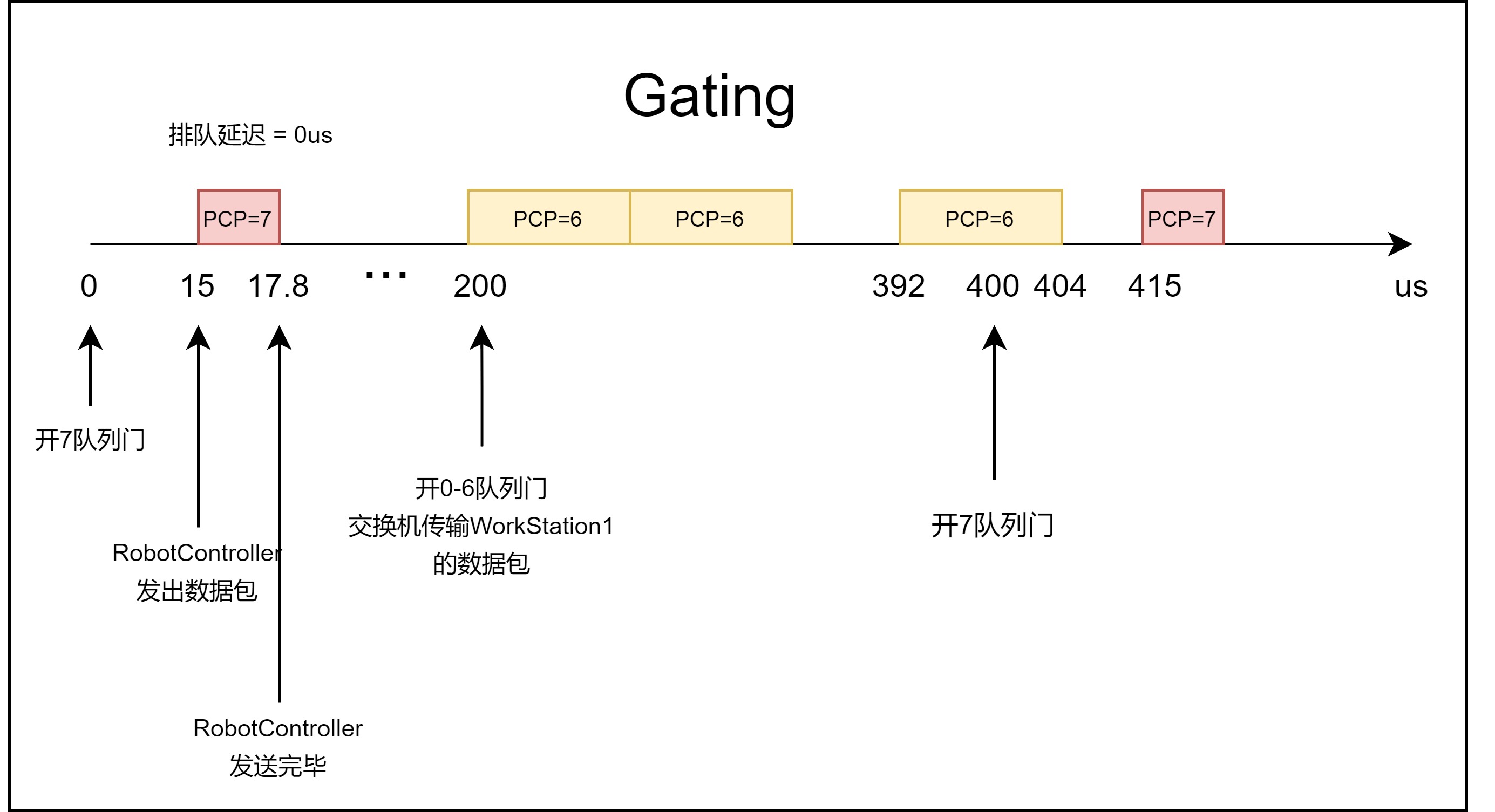
在有门控列表存在的情况下,0时刻WorkStation向交换机A发送数据包,其中WorkStation1的流量进入交换机A的3号端口6号队列,WorkStation2的流量进入5号队列。但此时5号队列和6号队列的门关闭,无法传输,流量缓存在队列中。当10us时,RobotController发送数据包,进入7号队列,此时7号队列的门打开,流量完成传输。当200us时,0-6号队列门打开,6号队列优先级高于5号队列,有先传输。由于开门周期内6号队列总是有流量,所以5号队列的流量无法完成传输。
在GCL存在的情况下,交换机专门将每个周期的前200us预留给RobotController发送流量,其流量不会产生排队延迟。但是由于GCL的存在,对于WorkStation1来说,网络带宽变成了StrictPriority带宽的一半。
4.4 帧抢占
4.4.1 example_frame_preemption.ini文件
此文件主要的区别在以下几条设定,主要是关于交换机队列是否是快速队列和交换机是否设置为可抢占。其余设定与example_strict_priority.ini文件相同。
1 | # 暂时不知道这边设置的具体含义,可能和设置7号队列可抢占,0-6号队列不可抢占有关 |
4.4.2 实验结果
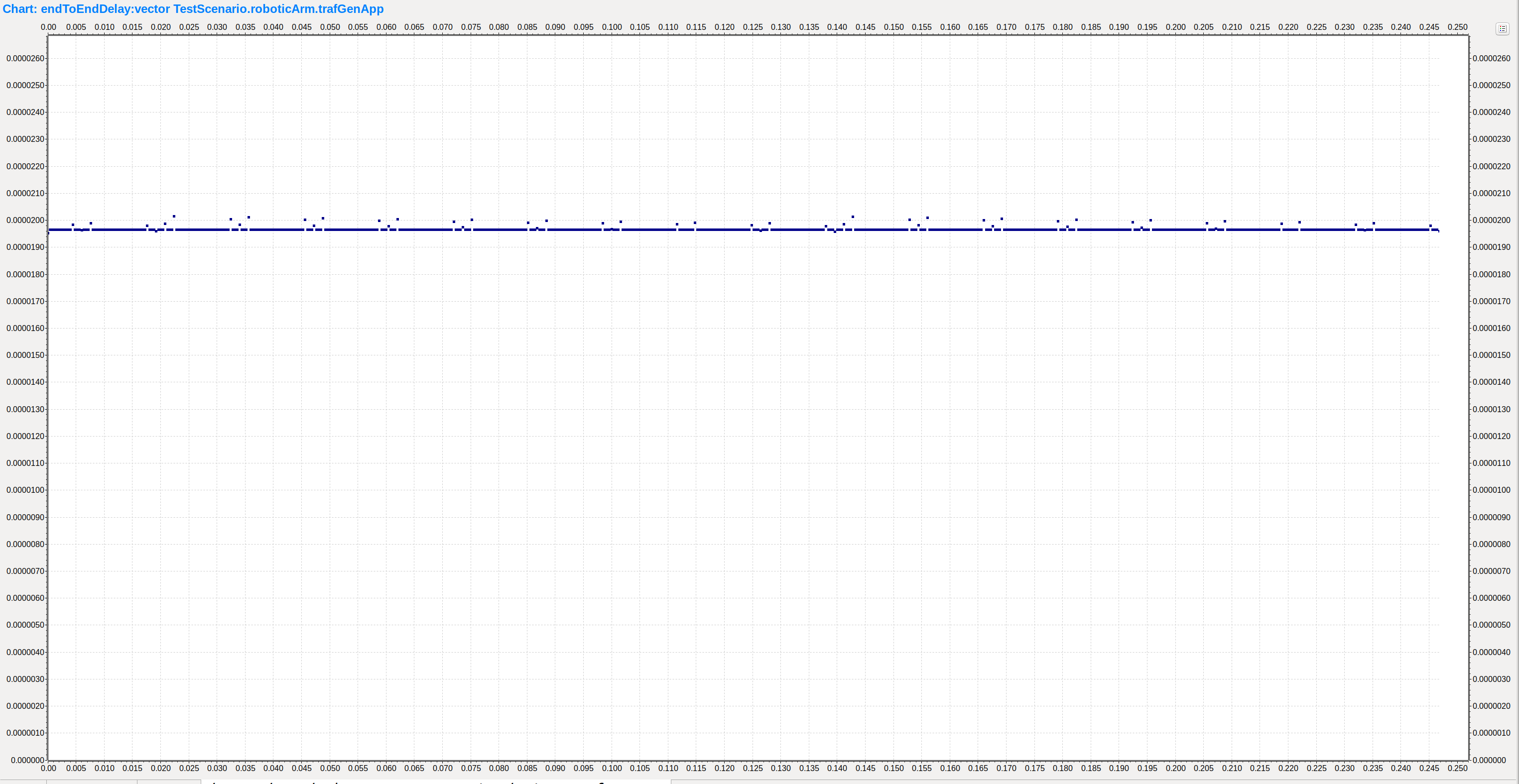
观察RoboticArm端应用程序统计的端到端延迟,可以看到延迟在19.5us附近有小幅度抖动。
workStation1流量带宽为:0.987Gbps (TestScenario.workStation1.eth.mac bits/sec sent =986945179)
SwitchA.eth[3]流量带宽为:1.01Gbps(TestScenario.switchA.eth[3].mac bits/sec sent = 1014668064) (注:流量带宽超过1Gbps原因未知)
robotController流量带宽为:0.0075Gbps (TestScenario.robotController.eth.mac bits/sec sent =7523725)
workStation2丢包率为:100% (TestScenario.switchA.eth[2].mac rx channel idle(%)=100)
4.4.3 小结
在帧抢占模式中,起始情况与严格优先级情况相同。当到达10us时,RobotController发送的流量达到交换机A的3号端口,此时交换机正在传输WorkStation1的流量,但高优先级帧抢占,终断正在传输的流量。当高优先级流量传输完成后,低优先级流量继续传输。
对于帧抢占模式,高优先级流量可以抢占正在传输的低优先级流量,从而减少排队时延,与严格优先级相比,其确定性更佳。但由于交换机处理帧抢占也需要一定的时间,所以其确定性略差与门控模式。但其可以保证网络的充分利用。

